
How Worlds Shape Intelligence
Large language model–based agents are moving from individual productivity tools into high-stakes organisational and societal domains. In these settings, the limiting factor is no longer raw intelligence, but reliability—how systems behave over time under real constraints.
Improving reliability requires learning shaped by feedback loops. Some of this learning occurs locally, through system-level design that reshapes context, constrains actions, and incorporates feedback without changing model weights. Other forms of learning must generalise beyond any single product or organisation, requiring environments that can be specified, evaluated, and reused independently of the systems they serve.
At this boundary, reinforcement learning environments become essential. Many important domains cannot be learned safely in production and instead require low-stakes simulations that mirror deployment conditions. These environments act as externalisable learning substrates, enabling reuse and selection pressure across systems.
Once learning substrates are externalised, coordination becomes a first-order problem. No single organisation can explore the full design space alone. Blockchains provide the coordination layer by enabling shared standards, discoverability, provenance, and economic alignment across a distributed ecosystem.
The central claim of this piece is that the future of reliable, real-world AI depends less on smarter models and more on how learning substrates are produced, selected, and coordinated.
__________________________________________________________________
The pace of progress in AI over the past few years has been unprecedented. Large language models (“LLMs”) have rapidly diffused into everyday use, enabling individuals to write, code, translate, research, and reason with a level of leverage that was previously inaccessible.
To date, individuals have benefited disproportionately relative to organisations. As Andrej Karpathy has argued, LLMs exhibit impressive breadth across many domains while remaining shallow and fallible. For individuals, this breadth represents a step-change—granting access to knowledge they did not previously possess. Organisations, by contrast, already employ specialised talent across functions; LLMs tend to augment existing capabilities rather than introduce net-new ones. Improvements in raw model intelligence alone, therefore, do not translate cleanly into organisational transformation.
This divergence reflects a broader shift in how progress in AI is achieved. For much of the past decade, advances were driven by scale. Beginning around 2020, LLM scaling laws formalised a simple rule: more parameters, more data, and more compute produced predictably better results. Pre-training budgets followed. Advantage accrued to those who could aggregate GPUs, secure power, and ingest the widest swath of the internet. As long as scale delivered returns, questions of data quality, provenance, and governance could be deferred.
“Data is the fossil fuel of AI.” -Ilya Sutskever
That era is now waning. Public web data is largely exhausted, while access to new data is tightening through platform restrictions, licensing regimes, legal pressure, and regulation. At the same time, architectural and training innovations diffuse rapidly. Distillation techniques allow smaller models to inherit much of the capability of state-of-the-art systems at a fraction of the cost, compressing the gap between leaders and followers. Compute remains expensive, but it is no longer a durable differentiator. Competitive advantage is shifting from how much one can train to what and how one trains.
Why Reliability, Not Intelligence, Now Limits Agents
As raw model capability converges, attention is moving downstream—from intelligence in isolation to behaviour in context. As AI systems transition from passive tools toward agents that act, decide, and persist over time, performance can no longer be judged by benchmarks alone. What matters is how systems behave across long horizons, under stress, and in interaction with humans, software, and institutions. Reliability, alignment, and adaptability become dominant constraints.
For enterprises, this manifests as risk. Once agents are embedded into production workflows, correctness alone is insufficient; behaviour must be predictable, auditable, and consistently aligned with organisational objectives.
More broadly, no single organisation can anticipate every edge case or encode every relevant objective upfront. Failures in deployed systems rarely stem from a lack of intelligence. They arise from distribution shift, ambiguous objectives, or poorly specified constraints. Addressing these failures requires continuous behavioural alignment, shaped by structured feedback loops rather than static evaluation.
These feedback loops capture tacit knowledge: how objectives trade off under pressure, how systems should fail gracefully, and how behaviour should adapt as conditions change. Learning, in this sense, becomes an ongoing process embedded in systems—not a one-off training event.
Context Engineering
Improving agent reliability does not always require changing a model’s weights. In many production systems, behaviour improves through changes to the surrounding system: how context is constructed, how feedback is captured, and how decisions are constrained over time. This class of techniques is referred to as context engineering.
Context engineering operates at the system level rather than the model level. Instead of modifying internal parameters via gradient descent, it shapes the information an agent receives and the structure of the environment in which decisions are made. This includes how state is represented, how memory is stored and retrieved, how tools and actions are exposed, and how feedback from users or downstream systems is incorporated into future interactions. Learning occurs not through retraining, but through the continuous refinement of the agent’s operating context.
If reinforcement learning teaches an agent how to act, context engineering determines what world the agent believes it is acting in.
This distinction matters because many real-world failures are not failures of reasoning, but failures of framing. Agents act on incomplete or incoherent representations of reality, pursue objectives that are underspecified, or attempt actions the surrounding system cannot actually support. Context engineering addresses these failure modes directly by tightening the interface between models and the systems in which they operate.
Klang
A clear example of this approach is evident in the design of the AI systems underlying SEED, an upcoming persistent society simulation from Klang Games, a BITKRAFT portfolio company. In SEED, autonomous agents live continuous lives—forming relationships, working jobs, and participating in civic structures—even when players are offline. While SEED is often described as an “agentic” world, its characters are not autonomous, self-improving reinforcement learners. Instead, they operate within a tightly engineered simulation in which learning occurs at the system layer rather than within model weights.
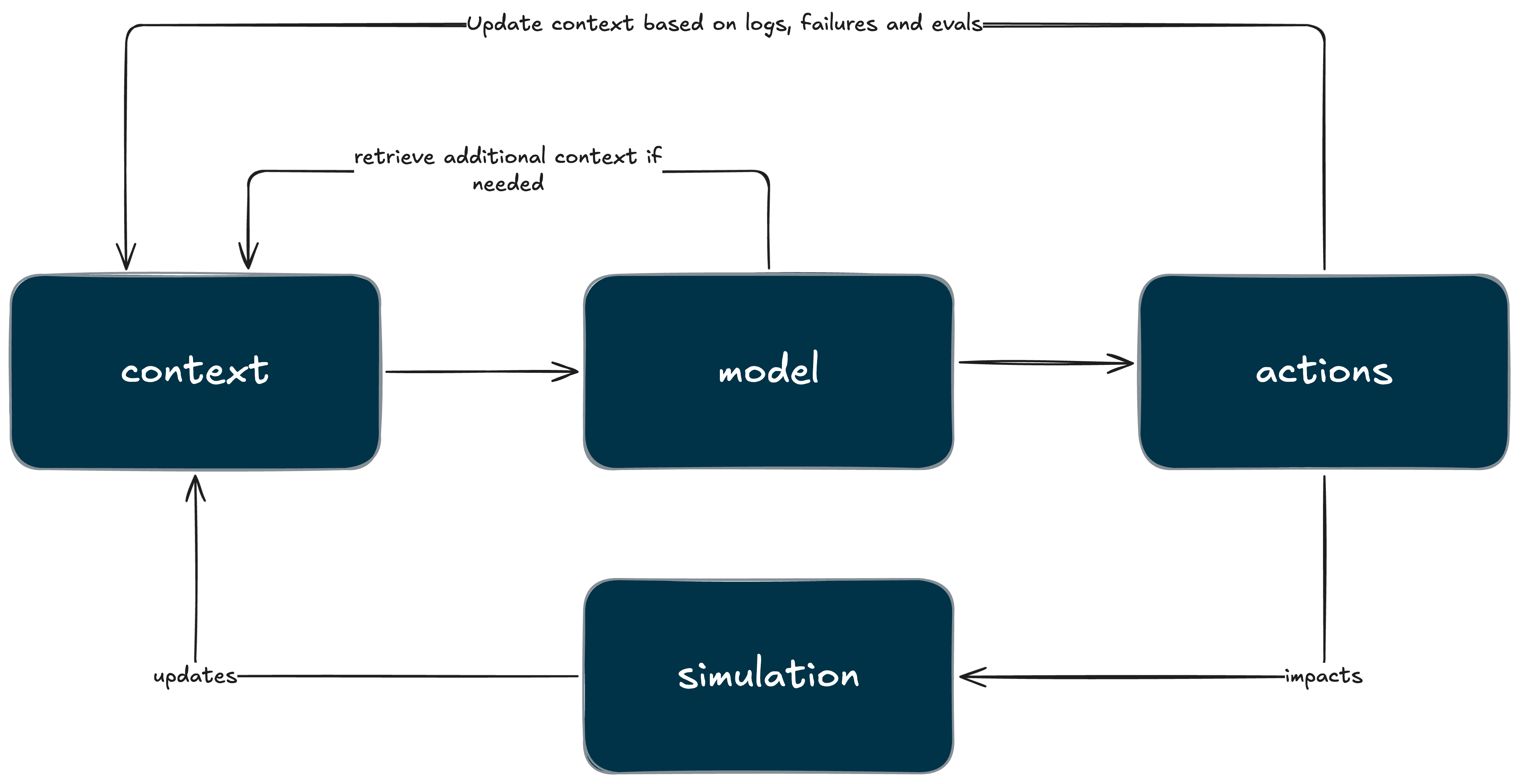
Klang does not run a reinforcement learning loop over agent behaviour. Their development loop is based on observability, diagnosis, and system tuning: logging agent behaviour, categorising failure modes, and iterating on how the world is presented to the model. Telemetry is used to identify where agents break down and to determine which part of the system should change next.
The dominant failure modes underscore the necessity of this approach. Many breakdowns occur at the interface between the simulation and the model: incomplete or incoherent context ingestion, mismatches between planned actions and executable affordances, or situations in which the model believes an action is possible but the world cannot actually execute it. These are not hallucinations in the usual sense; they are failures of world-to-model translation. Klang addresses them through strict action schemas, simulation-validated execution, and explicit feedback when actions are impossible—designed to ensure that agents remain coherent even under constraint.
At the architectural level, SEED relies on a hybrid model in which deterministic systems provide the safety rails, and LLMs provide narrative and intentionality. A Utility AI layer enforces core survival and prioritisation logic—hunger, rest, and safety—thereby maintaining predictability and robustness. The LLM operates within these constraints, selecting among already-safe options and expressing them coherently. In this setup, behaviour is not encoded in weights; it emerges from the interaction between a constrained model of the world and a carefully curated context.
TypeX
A different but complementary example is TypeX, another BITKRAFT portfolio company that is developing a privacy-first agent execution platform accessible directly via the software keyboard on Android and iOS devices. TypeX’s core primitive is not conversation, but intent. Rather than treating each interaction as ephemeral, the system progressively builds a structured, persistent representation of the user over time—an intent graph that captures preferences, goals, and patterns across sessions.
Here, context engineering takes the form of memory architecture. TypeX explicitly separates long-term, on-device memory—used for user profiling and intent inference—from short-term conversational context used for immediate disambiguation. Small language models (“SLMs”) run locally to maintain this persistent user state, preserving privacy and reducing latency, while cloud-based systems handle execution and API orchestration. The result is a system in which intelligence is distributed across layers, each optimised for different constraints.
Crucially, TypeX does not rely on language models to “know” facts about the world. Instead, inferred intent is routed through an agent layer that selects authoritative external APIs for execution. When a user invokes an agent to check a flight status, the model does not reason its way to an answer—it identifies intent, selects the appropriate data source, and returns structured information from a system of record. This aims to reduce ambiguity and hallucination risk by constraining the world the model is allowed to act within.
As with Klang, learning in TypeX occurs through system iteration rather than autonomous self-modification. Intent signals are accumulated over time, memory representations are refined, and execution pathways are expanded incrementally. Fine-tuning plays a secondary role, primarily to reduce latency or cost, not to encode behavioural logic. Behaviour lives in the architecture and context, not in the weights.
Limitations of Context Engineering
The above examples illustrate the power of context engineering. By tightly controlling information flow, action affordances, and feedback loops, organisations can achieve substantial gains in reliability and alignment without continual retraining. These systems are fast to iterate, closely coupled to product objectives, and well-suited to production environments where latency, predictability, and user trust are paramount.
However, this strength is also their limitation.
Context engineering is inherently product-specific. Context is defined relative to a particular system architecture, set of objectives, and internal state. The feedback that shapes behaviour is local, tied to the dynamics of a single product or platform. As a result, improvements compound within organisations but produce few spillovers beyond them. Each company constructs its own world for agents to inhabit, and the learning that occurs inside that world is not meaningfully portable.
Learning becomes an ecosystem-level concern only once it must generalise beyond any single constructed world. Externalisable learning substrates—such as RL environments—can operate at this boundary. They do not necessarily dictate how agents behave within a system. Instead, they can be used to shape which tasks, constraints, and failure modes become focal points for learning across systems.
By enabling reuse, comparative selection, and knowledge spillovers without exposing proprietary context, shared substrates allow learning to compound across organisations while preserving firm-level defensibility. Context engineering determines how an agent experiences a world; externalisable learning substrates determine which worlds are worth learning from. It is at this boundary—where learning must be shared, compared, and reused—that coordination becomes a first-order problem.
Reinforcement Learning: An Externalisable Learning Substrate
Once learning must generalise beyond any single constructed world, system-level iteration alone is no longer sufficient. At this boundary, reinforcement learning environments emerge as the primary externalisable substrate through which agent behaviour can be shaped.
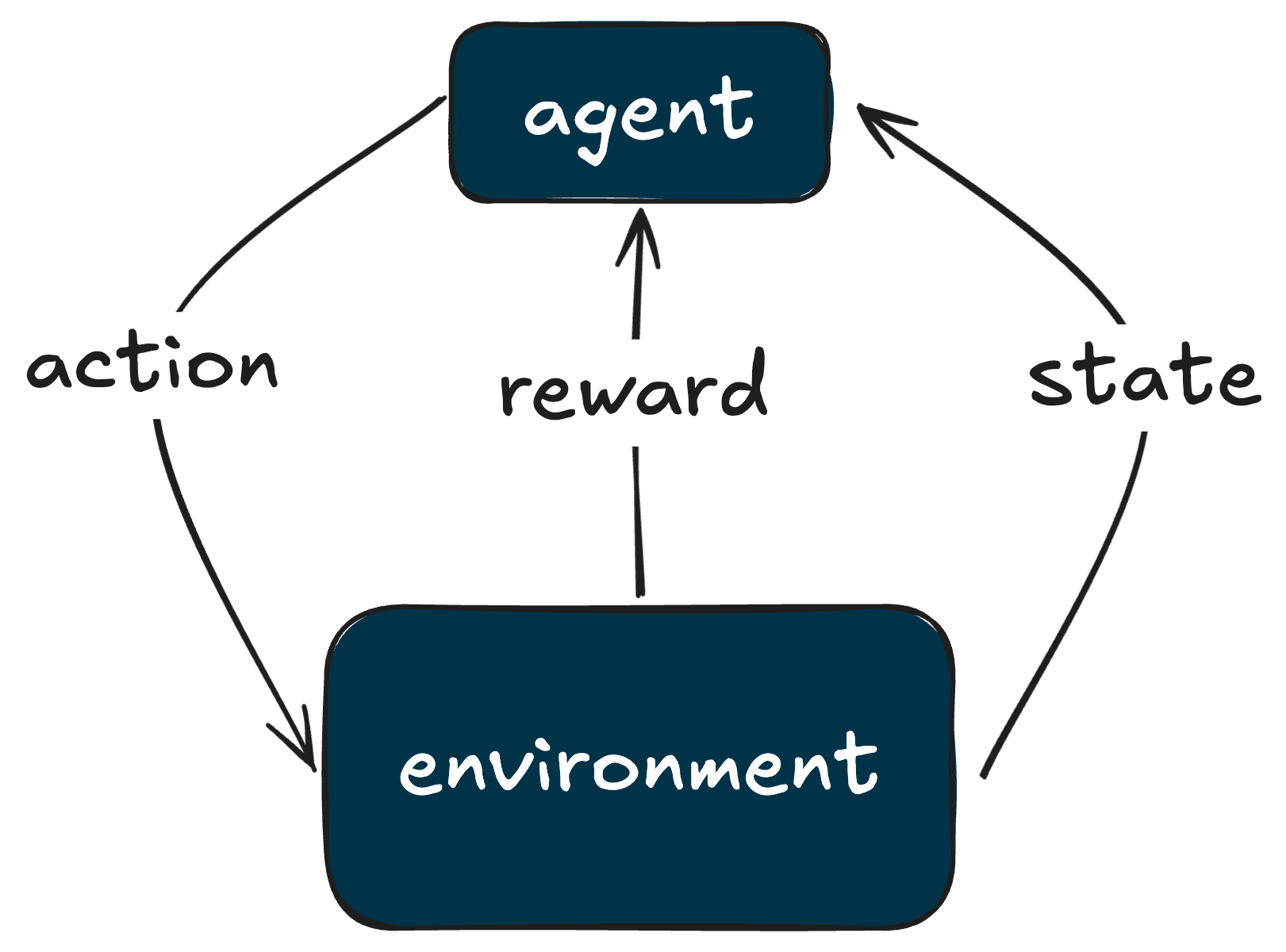
Reinforcement learning optimises behaviour through repeated interaction with a structured environment that encodes tasks, constraints, and feedback. Unlike context engineering—which reshapes how an agent experiences a particular world—RL environments specify the world itself. They define what actions are possible, how success is measured, and which failure modes matter.
In this sense, RL gyms are not merely training tools. They are shared representations of problem domains: formalised abstractions of workflows, interfaces, physical constraints, or decision processes that agents are expected to master. Because these representations can be specified independently of any single product or organisation, they can be reused, compared, and iterated on across systems.
Synthetic Reality
At BITKRAFT, this framing sits within our broader Synthetic Reality thesis: as our lives become increasingly digitised, reality itself becomes a blend of physical systems, software interfaces, and simulated environments. We back founders who build on this frontier, from immersive digital worlds and games, to interactive consumer applications, to the infrastructure that underpins it all.
Games have long demonstrated how complex behaviour emerges from clear rules, constraints, and feedback. RL environments apply the same philosophy beyond entertainment—to business workflows, product journeys, medical diagnosis, and other real-world domains. An RL gym modelling a corporate workflow might include API response times, database schemas, KPIs, or user interface logic, creating a high-fidelity digital twin in which agents can be trained safely.
Context engineering operates within these worlds, shaping how agents perceive and act. RL environments determine which worlds are constructed in the first place. Together, they define the terrain on which agent behaviour is formed.
The Structural Bottleneck and the Opportunity It Creates
“When somebody asks me how many models should there be, I’ll say as many models as firms in the world." -Satya Nadella (All-In Podcast)
As agents move deeper into real-world domains, the limiting factor is no longer access to models, but access to learning substrates that reflect the diversity of tasks, constraints, and failure modes encountered outside any single organisation. Each firm possesses its own tacit knowledge, but no firm can define the full space of environments agents must learn to operate within.
The implication is not that every organisation must build everything itself, but that learning must be shaped across many independent worlds. Reinforcement learning environments provide a mechanism for doing this, but only if they can be created, evaluated, and iterated on beyond the boundaries of a single team or platform. The breadth of potential domains—from enterprise workflows to scientific research to hyper-local logistics—makes a centralised approach impractical. No single actor can anticipate which tasks will matter most, or which failure modes will prove decisive.
While the process of constructing environments will increasingly be automated—often with AI systems assisting in the generation of tasks, simulations, and reward structures—the underlying training remains compute-intensive. Large-scale reinforcement learning requires sustained access to hardware, reproducible execution, and the ability to run many parallel experiments under controlled conditions. Aggregating this infrastructure is itself a coordination problem, particularly if access is to be broad rather than restricted to a handful of well-capitalised players.
Decentralisation addresses this challenge not by making environment creation harder, but by making it more open. A permissionless ecosystem allows many independent contributors to define tasks, specify success and failure modes, and propose reward structures without being bottlenecked by a single creator or curator. Over time, selection pressure determines which environments are actually useful: those that consistently improve downstream behaviour attract usage and investment, while weaker or redundant environments fall away.
This dynamic mirrors the evolution of other open systems. Progress emerges not from perfect upfront design, but from broad experimentation coupled with credible mechanisms for selection. The structural opportunity, then, is not merely to host more environments, but to coordinate their creation, evaluation, and reuse in a way that allows learning to compound across the ecosystem.
Doing so requires infrastructure that can aggregate compute, make contributions legible, and align incentives without central control. It is at this layer—where permissionless participation, selection pressure, and capital allocation intersect—that blockchain networks become structurally relevant.
The Structural Solution
Once learning substrates are externalised, coordination becomes the dominant constraint. Distributed systems face a cold-start problem: supply is needed to attract demand, but demand rarely appears without supply already in place. Blockchains address this by issuing tokens—claims on future network value—that incentivise early participation and allow coordination to emerge before utility is fully realised. This mechanism has already proven effective in coordinating global resources such as compute, storage, and data collection, and it applies equally to externalised learning infrastructure.
ORO
The ORO protocol, built by Midcentury, a BITKRAFT portfolio company, has positioned itself as “the coordination layer for real-world superintelligence”. ORO is an open, permissionless network designed to collect, verify, and standardise real-world data across application-specific subnets, making it usable across training, RL environments, evaluation, benchmarking, and synthetic data generation.
The core premise is simple. While public internet data is increasingly exhausted, real-world data remains abundant. Enterprise workflows, computer use, games, robotics, and healthcare systems all generate potential learning signal. The difficulty is not access but rather turning this heterogeneous data into a form that models can reliably learn from. That requires pipelines that can structure data, verify its quality, and connect it to downstream learning processes in a high-signal, reusable form.
Decentralisation matters here for two practical reasons. First, large-scale training runs and environment rollouts are compute-intensive. Coordinating distributed infrastructure allows ORO to aggregate the resources needed to execute these workloads without relying on a single operator. Second, decentralisation removes bottlenecks around what gets defined. Permissionless contributors can introduce new tasks, specify success and failure modes, and propose reward structures without being constrained by a central curator. This expands the space of possible environments and increases selection pressure, allowing the most useful tasks and data pipelines to surface through use.
To make this possible without sacrificing privacy or trust, ORO relies on a verification-first architecture built on trusted execution environments (“TEEs”). Data is encrypted locally and decrypted only transiently within TEEs for specific tasks, enabling access to categories of real-world data—such as enterprise or healthcare data—that are inaccessible to most platforms. The same TEEs execute standardised validation and scoring functions that apply uniformly across all subnets, producing cryptographic attestations that prove data quality. Once verified, data and associated tasks can be reused across multiple learning contexts and valued based on measured properties, with provenance and compensation enforced onchain.
Mira Network
Blockchains can also coordinate AI primitives beyond learning substrates themselves. A complementary example is Mira Network, another BITKRAFT portfolio company, that focuses on inference-time evaluation rather than training.
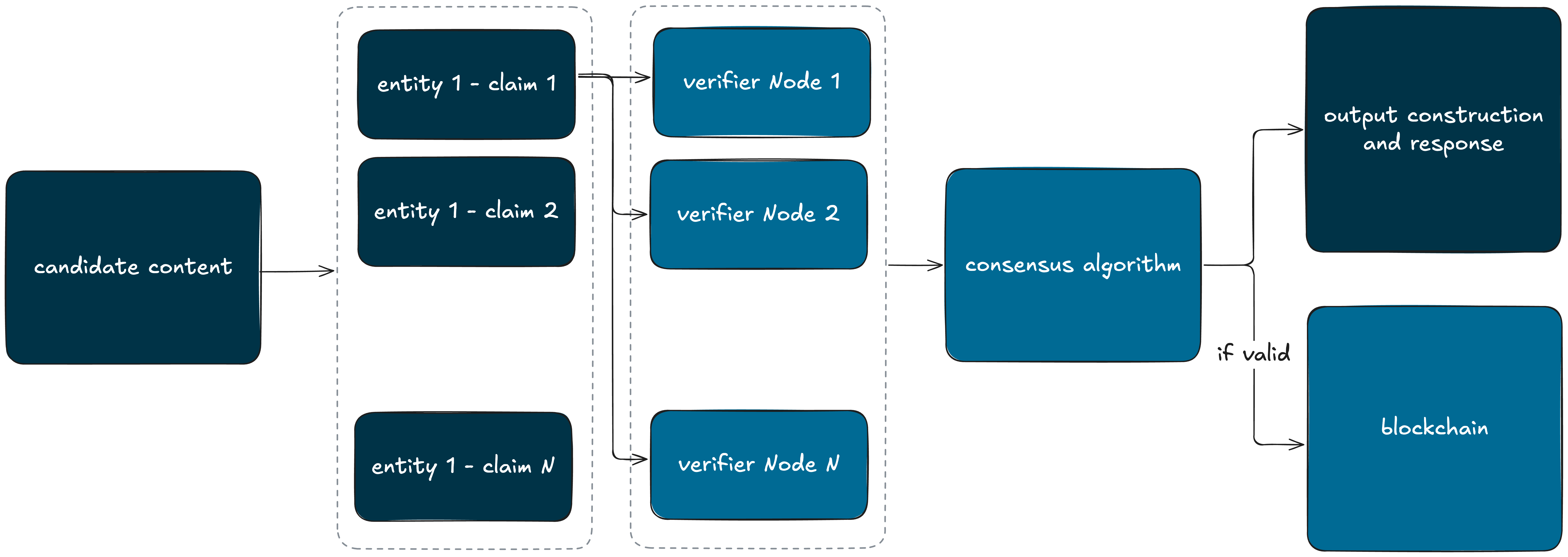
The Mira Network implements a decentralised system for verifying AI outputs by decomposing them into atomic, verifiable claims and distributing their assessment across many independent nodes. Each node runs its own verifier model, with outcomes determined through network-wide consensus. Economic incentives are designed to ensure that honest evaluation is the dominant strategy, while cryptographic certificates record verified results as immutable, reusable facts. While Mira does not directly coordinate learning, it demonstrates the same structural principle: blockchains can coordinate critical AI infrastructure—such as evaluation and truth verification—under adversarial conditions without reliance on a central authority.
Blockchains make AI infrastructure legible
Taken together, these systems illustrate how blockchains make AI infrastructure legible and composable. Onchain registries provide shared discovery. Cryptographic attestations make quality verifiable without trust. Shared schemas and interfaces allow independently built components—datasets, environments, evaluators, verifiers, or future learning substrates—to interoperate. Smart contracts enforce attribution, usage terms, and value flow by default. Once resources are discoverable and rights-aware, blockchains can also function as the payment layer. Using open standards such as x402, payments can be metered directly to usage—per task, per training run, per evaluation, or per episode—enabling open task markets rather than coarse subscriptions or bilateral contracts.

When performance becomes observable and verifiable, capital formation and speculation have historically followed. Externalised AI primitives generate persistent signals—usage, quality, and impact—that markets can price. A concrete example is Delphi, developed by the Gensyn team, which applies prediction markets to machine intelligence. In Delphi, models compete on benchmarks while participants take positions on which systems they expect to perform best. As evaluations run, prices update continuously, producing a real-time market signal of performance. Over time, such mechanisms allow capital, attention, and experimentation to concentrate around the most effective primitives, reinforcing selection pressure without central gatekeeping.
The result is an ecosystem in which experimentation is broad, signal is credible, and coordination emerges from shared infrastructure rather than institutional control.
Sounding Off
The transition to an agentic economy forces a redefinition of what progress in AI actually means. As model architectures converge and returns to pre-training diminish, raw capability no longer compounds as it once did. The decisive factor shifts downstream: whether learning can be grounded in systems that reflect the constraints, incentives, and failure modes of the real world.
This creates a clear bifurcation. Organisations that embed feedback loops—through context engineering, simulations, and shared external learning substrates—enable agents to accumulate domain-specific competence that compounds over time. Those that rely primarily on general-purpose models, detached from high-fidelity environments and evaluation, will plateau quickly. We believe the gap between the two will widen, not narrow.
The implication is that environment construction and learning substrate design are no longer ancillary concerns. They emerge as a strategic layer of the AI stack: path-dependent, increasingly reusable, and central to long-term advantage. Once an environment, dataset, or evaluation regime becomes a standard training ground, its value accrues across every model and application that passes through it. Advantage compounds not at the point of inference, but upstream, in the conditions under which agents learn.
The open question, then, is not whether this shift will occur, but how these substrates are produced and governed. Centralised ownership limits diversity and slows iteration. Pure open-source models struggle to sustain infrastructure of this complexity. What is required is a coordination mechanism that supports experimentation, selection pressure, and capital formation simultaneously.
Blockchains offer one such mechanism. By making contribution, verification, and reuse economically legible, they allow learning quality—rather than institutional power—to determine adoption. Over time, this enables markets in learning substrates where capital, talent, and usage flow toward the environments and primitives that demonstrably improve downstream performance.
If this model holds, the centre of gravity in AI will continue to move: from models, to data, to environments—and ultimately to the systems that coordinate them. We believe the organisations that recognise this early will not simply deploy agents faster. They will shape the conditions under which agents learn at all.
—
For disclosures, visit http://bitkraft.vc/legal

